
LightingRL
Collection
Diffusion Large Language Models with a SOTA Accuracy–Parallelism Trade-off • 7 items • Updated • 2
docker run --gpus all \
--shm-size 32g \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=<secret>" \
--ipc=host \
lmsysorg/sglang:latest \
python3 -m sglang.launch_server \
--model-path "SJTU-DENG-Lab/LightningRL-8B-b32-MATH500" \
--host 0.0.0.0 \
--port 30000# Call the server using curl (OpenAI-compatible API):
curl -X POST "http://localhost:30000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "SJTU-DENG-Lab/LightningRL-8B-b32-MATH500",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
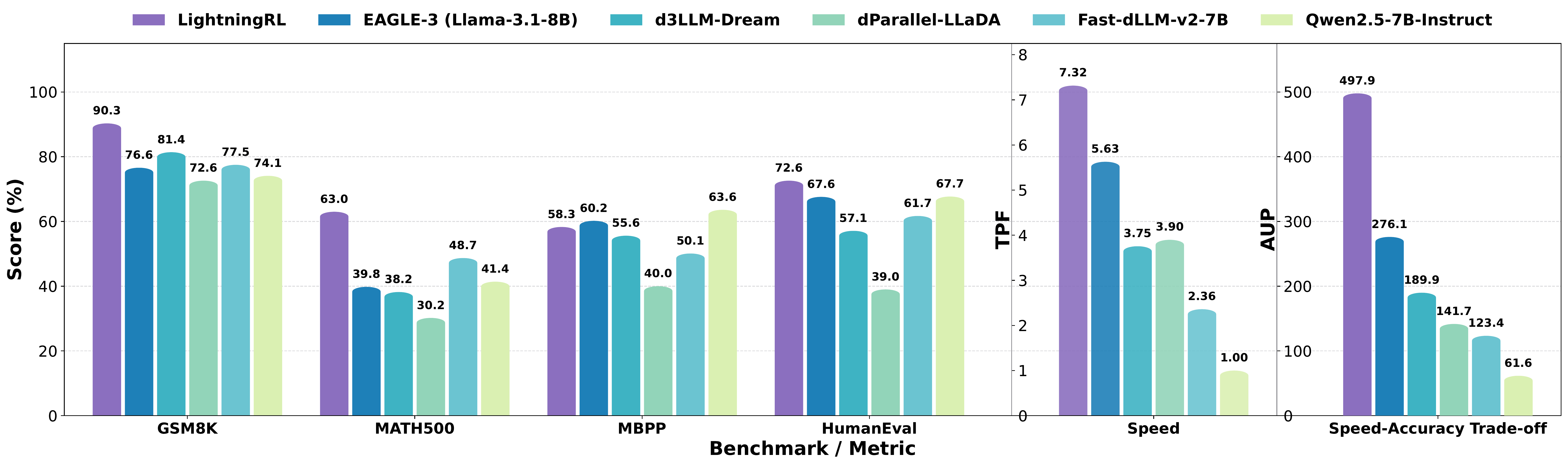
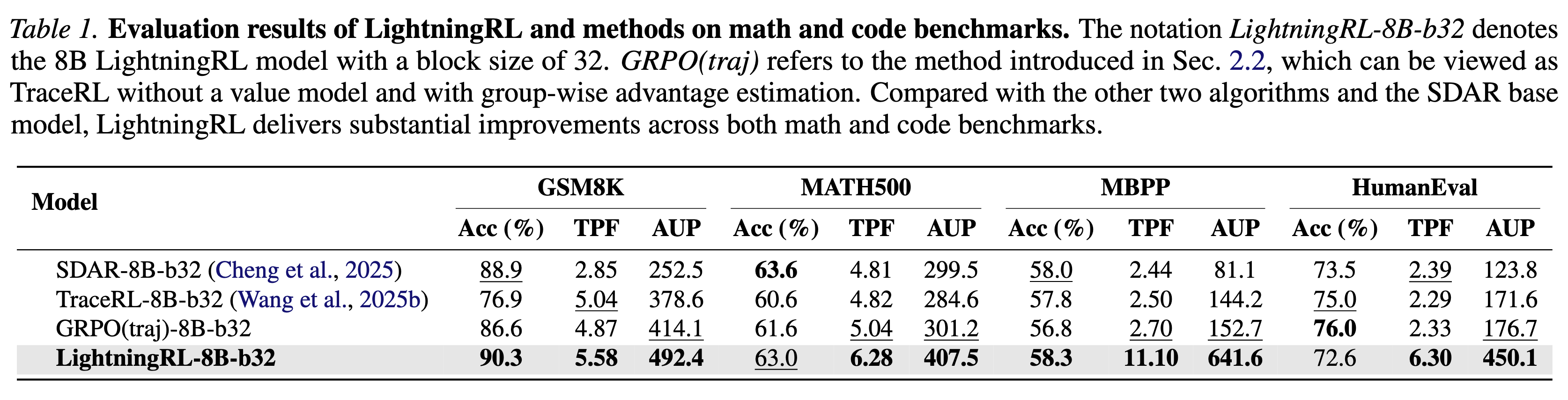
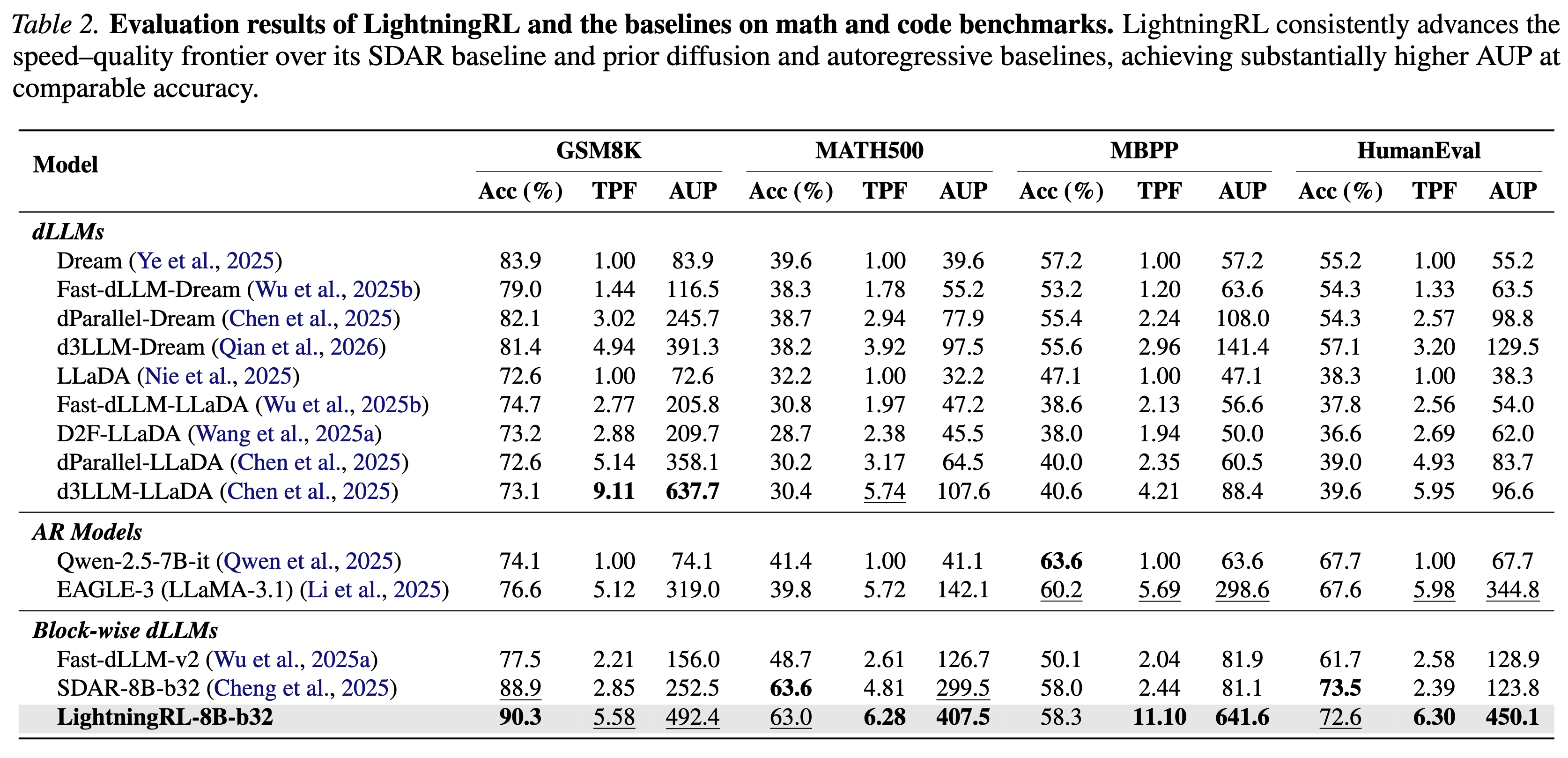
}'We introduce LightningRL, a reinforcement learning post-training framework for block-wise diffusion Large Language Models (dLLMs) that breaks the accuracy–parallelism trade-off. Applied to SDAR-8B, LightningRL achieves 7.32 average TPF and 497.9 AUP — simultaneously improving both generation quality and inference speed.
@misc{hu2026lightningrlbreakingaccuracyparallelismtradeoff,
title={LightningRL: Breaking the Accuracy-Parallelism Trade-off of Block-wise dLLMs via Reinforcement Learning},
author={Yanzhe Hu and Yijie Jin and Pengfei Liu and Kai Yu and Zhijie Deng},
year={2026},
eprint={2603.13319},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2603.13319},
}
Install from pip and serve model
# Install SGLang from pip: pip install sglang# Start the SGLang server: python3 -m sglang.launch_server \ --model-path "SJTU-DENG-Lab/LightningRL-8B-b32-MATH500" \ --host 0.0.0.0 \ --port 30000# Call the server using curl (OpenAI-compatible API): curl -X POST "http://localhost:30000/v1/chat/completions" \ -H "Content-Type: application/json" \ --data '{ "model": "SJTU-DENG-Lab/LightningRL-8B-b32-MATH500", "messages": [ { "role": "user", "content": "What is the capital of France?" } ] }'